Defining biocomputing in a few sentences remains a challenging task.
This is because biocomputing is an emerging field. And as it usually happens with new technological areas, it takes time to establish their definition and understanding.
For example, when looking up Wikipedia for Biocomputing, we land on a disambiguation page that proposes two definitions: biological computing and bioinformatics.
An additional challenge is created by the fact that biocomputing is widely an interdisciplinary field, as ‘bio’ and ‘computing’ represent two very different domains – biology and computer technology. These two fields were treated as separate for many decades, and eventually, started to merge in different ways:
Biology
Biology is becoming less ‘wet lab’ research, where researchers used to perform mainly manual experimental work. Technology is becoming more and more important in biology research; more manual work is done by robots and more data is being analyzed by AI systems. This gives a biologist the possibility to do more. However, it also requires embracing new fields, which calls for new sets of skills, such as coding and finding new ways to synthesize a large amount of data.
Computer technology
Computer technology may soon not be purely the matter of silicon and wires in which electrons flow to process the information. There are a lot of attempts to develop new hardware to solve the problem of energy consumption, which arises with the fact that we are using more and more data. Among those attempts, we could list:
Quantum computing
This can extend the information processing to not only electrons but also photons, used as particles or waves.
Neuromorphic computer
This takes inspiration from biology on effectively processing information. Here, the human brain is a golden standard for building new circuits, from different materials and with different topologies. In these new circuits, mainly electrons (as in classical computers) and photons (as in photonic computing) are used to process information.
Biocomputing
Here, the elements of biology are used as a part of the computation system. We go beyond electrons and photons to use other units of information. We don’t try to ‘build a computer inspired by a human nervous system’ but we use the biological
The biological elements which process the information in living organisms can be seen on different levels:
- Ions
- Molecules
- Cells
- Organs
- Animals and humans.
This raises an interesting question:
How do we distinguish biocomputing from other applications, where biology meets computation, such as biological research?
This is further complicated by two other factors, making the definition of biocomputing even more challenging:
- The variety of organic matter that can potentially be used for biocomputing, and
- The fact that not every case of the combination of an organic matter and computation systems could be called biocomputing.
How do we distinguish biocomputing from other applications, where biology meets computation, such as biological research?
Still, there are many situations where using computing hardware on the biological components is not considered biocomputing. Here are some examples:
- For DNA: When we use computers to analyze the pictures from DNA electrophoresis.
- For bacteria: When we use AI-powered imaging systems to detect bacteria
- For living cells: when we measure the electrophysiological activity of neurons, to study the mechanisms of Alzheimer’s disease, and when we use a live recording from living cells or other living objects and track them with AI on the screen.
- For organoids: When we use the organoids to study the mechanisms of diseases.
- For whole organisms: When we collect real-time activity data from an animal or human, and when we collect EEG signal.
So, how do we know if a given system combining computation and biological matter is biocomputing or not?
We think that the intention of the computing makes the difference. If the intention to use biological matter in combination with computer technology is to observe a biological process, then it’s not biocomputing. On the other hand, if the intention is to solve a mathematical problem (for example, to build logic gates), it’s biocomputing.
We can therefore propose the definition for biocomputing as Any form of computing that is done on a system combining (I) computer technology and (II) biological components which is not an end user, nor an observation object of this computing system.
How do we do biocomputing at FinalSpark?
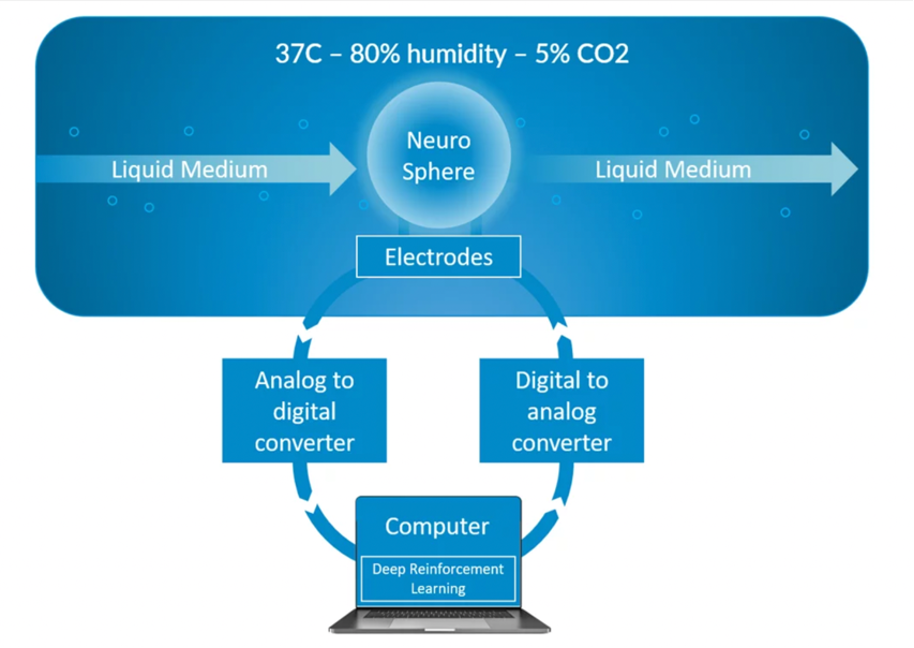
At FinalSpark, we use living cells, specifically, human neurons obtained from iPS cells, to perform computations. We strive to store data and perform logic operations using neurons as circuits.
For over three years, we’ve been undertaking the approach of using neurospheres, which are artificially created 3D structures of living neurons. They do not resemble the human brain in any form except for the building blocks: neurons. We do not aim to rebuild any brain structure or to solve problems of biological research, such as understanding the human brain or finding cures for diseases. The main objective of FinalSpark R&D is to make it possible to use neurons as computation units.
For example, one of our current challenges is to build logic gates by modifying the connections within the complex 3D structure of a neurosphere.
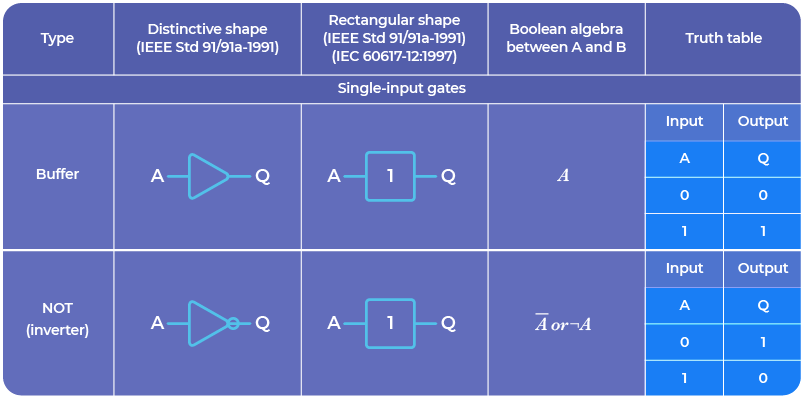
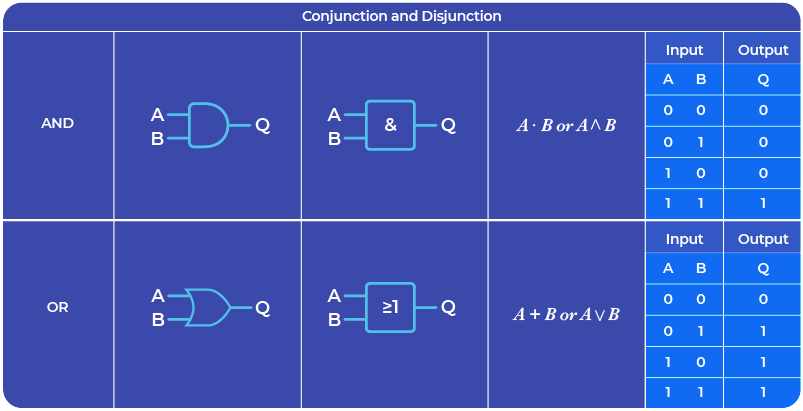
However, technically, it is also possible to use the FinalSpark platform to study biology, for example, neurotoxicity. This is not biocomputing – it is an application of our platform outside biocomputing. It uses the same components (neurons, FinalSpark platform), but it’s a different application. As mentioned earlier, we believe that all that makes a difference is the intention for which the platform and components are used.
Therefore, we can say that the FinalSpark platform can be used for biocomputing and other applications.